Abstract
- Token의 개수를 수조개로 늘림
- 파라미터의 개수는 7B(70억) 개로 줄었음
- 저작권 없는 오픈된 데이터셋 사용
- 다른모델과 비교하여 SOTA 달성
1 Introduction
- GPT, BERT등 많은 Large Language Model에서 파라미터 갯수를 놓여 → 성능을 높임
- 파라미터가 많다고 해서 무조건 좋은 모델은 아니라는 연구결과 있음
- BEST성능을 내는 파라미터갯수를 찾는 것이 목표
- Train 속도가 빨라 지는것은 아니지만 추론시간은 줄어드는 장점이 있음
- 그결과 7BG ~ 65B범위의 경쟁력있는 BEST모델을 찾음 이를 LLaMA라고 정의
- LLaMA-13B 모델에서 GPT3를 능가(GPT3 파라미터 175B보다 약 10배이상 작음)
- SINGLE GPU에서 돌아 갈수 있기 때문에 연구적으로나 대중화 가능성이 있다.
- 가장 큰사이즈인 LLaMA-65B는 Chinchilla 또는 PaLM-540B과 같은 대형 언어 모델과도 견주어 볼수 있음
- Chinchilla, PaLM, or GPT-3와는 다르게 공개된(저작권이 없는?) 오픈된 데이터를 사용하기 때문에 오픈소스와 호환(?) 가능하다
- 아키텍처에 맞게 수정한 Transformer 및 훈련 방식, 모델의 성능 소개
2 Approach
- Traing 방식은 기존의 GPT 와 동일 ( 현재 토큰 time t에서 t+1의 토큰 예측 )

pretrain data
English CommonCrawl [67%]
- CCNet pipeline 과 함께, 2017년부터 2020년까지의 5개의 CommonCrawl dumps 사용
- line 레벨에서 중복되지 않는 data 사용
- fasttext를 사용하여 영어롤 이루어지지 않은 문서 제거
- ngram language modeling 을 사용하여 퀄리티가 떨어지는 문서 삭제
- 위키백과에서 reference로 사용되는 페이지를 무작위로 샘플링한 페이지와 reference로 분류되지 않은 페이지를 분류하는 선형 모델을 교육했습니다.
C4 [15%]
- CommonCrawl을 전처리 하여 사용하였을때 성능이 향상되는 것을 확인하여 공개된 C4 데이터셋 추가
- 중복제거, 언어식별 → (영어가 아닌 문서 제거)
- CCNet과 다른점은 퀄리티 필터링(문장 부호의 존제여부, 웹페이지의 문장의 단어수)은 휴리스틱에 의존적
Github [4.5%]
- Google BigQuery에 공개된 Github Dataset 사용
- Apache, BSD, MIT 라이센스 프로젝트만을 사용
- 문장 길이 또는 알파벳 캐릭터 비율에 따라 휴리스틱 방식으로 저 퀄리티 파일 필터링
- 주석, 머릿글 같은 상용어구가 정규식으로 제거됨
- 파일레벨에서 결과 데이터셋을 중복 제거
Wikipedia [4.5%]
- 2022년 6월부터 8월까지 라틴어 또는 키릴 문자를 사용하는 20개의 위키백과 덤프를 추가
Gutenberg and Books3 [4.5%].
- 훈련 데이터 셋에 두 가지 북 말뭉치를 포함
- 구텐베르크 프로젝트
- 언어 모델을 훈련하기 위해 공개적으로 사용할 수 있는 dataset인 더 파일의 북스3 섹션
- 중복되는 내용이 90% 이상인 책을 제거 하여 중복제거
ArXiv [2.5%]
- 첫번째 섹션이전 항목, 참고문헌 제거
- .tex 파일에서 주석제거
Stack Exchange [2%]
- 높은 퀄리티의 Stack Exchange 질문과 답변, 서로 다른 분야인 CS부터, 화학까지 사용
- 28개의 대형 사이트에서 HTML 태그를 제거함
Tokenizer
- BPE: SentencePiece의 Byte-Pair-Encoding 토크나이저 사용
- 14조개의 토큰을 가지
2.2 Architecture
Pre-normalization [GPT3]
- SubLayer 의 Output을 RMSNorm normalizing function으로 교체
SwiGLU activation function [PaLM]
- activation funtion relue → SwiGLU activation function 사용
Rotary Embeddings [GPTNeo]
- Positional Embedding 대신 Rotary positional embedding 사용
2.3 Optimizer
- AdamW optimizer 사용 파라미터는 아래 표 참조
- hyper-parameters: β1 = 0.9, β2 = 0.95.
- cosine learning rate schedule, such that the final learning rate is equal to 10% of the maxi-mal learning rate.
- weight decay of 0.1, gradient clipping of 1.0. 2, 000 warmup steps
세부적인 hyper parameter

효율적인 구현
모델의 교육 속도를 향상
- 일반적인 multi-head attention을 사용하여 메모리 사용량과 runtime 속도 개선 하기 위해 다음 라이브러리 사용 https://github.com/facebookresearch/xformers
- 80GB RAM을 장착한 2048 A100 GPU에서 약 380개의 토큰/초/GPU를 처리 1.4T 토큰 약21일 소요
3. Main results

Zero-shot.
- 텍스트 와 테스트 예제를 사용하여 Open-ended답변을 생성하거나 제안된 답변의 순위를 지정
- 태스크에 대한 예시는 주지 않고, 태스크를 설명하는 자연어 문구만을 준다. 이 방법은 엄청나게 편리할 뿐만 아니라 잠재적으로 강건하고 사전학습 데이터에 편재할 수 있는 좋지 않은 상관관계를 피하게 한다.
Few-shot.
- 1 부터 64개의 task의 몇가지 예제와 테스트 예졔를 제공
- 모델은 입력과 답변을 생성하거나 여러가지 선택지의 랭크 생성
- detail)
- 모델은 예시 태스크를 보게 되지만,
- "한국어를 영어로 번역하라: 집에 가고 싶어 -> I want to go home. 배고파 -> I am hungry 치킨 사줘 -> _______ "
Common Sense Reasoning - 상식 추론
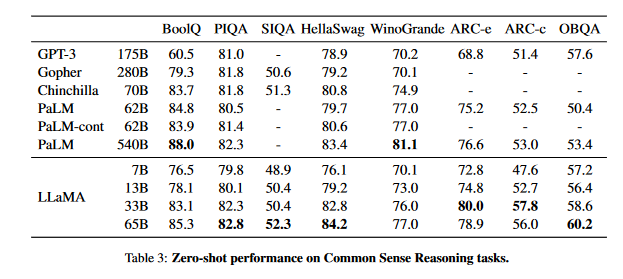
eight standard common sense reasoning benchmarks:
- BoolQ (Clark et al., 2019),
- PIQA (Bisk et al., 2020),
- SIQA (Sap et al., 2019),
- HellaSwag (Zellers et al., 2019),
- WinoGrande (Sak-aguchi et al., 2021),
- ARC easy and challenge (Clarket al., 2018)
- OpenBookQA (Mihaylov et al.,2018).
- language modeling community에서 수행된 제로샷 세팅에서 평가
Closed Book QA (Multi Information Extraction)
Closed Book 문서에서 정보 선택
- open-book : 질문과 지문이 주어지거나, 질문에 맞는 지문을 찾고, 모델이 해당 지문에서 정답을 찾는 문제
- closed-book : 대용량의 데이터를 학습한 모델에 질문을 입력 시 정답을 찾는 문제 (모델 자체가 정답을 기억)
- https://velog.io/@changyong93/9%EA%B0%95-Closed-book-QA-with-T5
Natural Question

TriviaQA

- Reading Comprehension
- 중고등학교 중국인 학생을 위해 설계된 영어 읽기 이해 시험에서 수집

Mathematical reasoning
- MATH
- LaTeX로 작성된 12K 중학교 및 고등학교 수학 문제의 데이터 세트
- GSM8k
- 중학교 수학 문제 세트
- Minerva는 ArXiv및 Math Web Pages에서 추출된 38.5B 토큰에 대해 fine-tuning된 PaLM 모델
- PaLM및 LLAMA는 수학 데이터에 대해 미세 조정되지 않음
- 문제에 대해 k개의 샘플을 생성하고 다수결 투표를 수행하는maj1@k. ma j1@k 평가, 그렇지 않은것 비교

Code generation
- HumanEval(Chenet al., 2021)과MBPP
- pass@k metric는, 모델로 하여금 K개의 샘플을 만들게 하고, 이 중 하나라도 문제를 해결하면 맞다고 하는 지표

Massive Multitask Language Understanding
MMLU: 인문학, STEM 및 사회 과학을 포함한 다양한 지식 영역을 다루는 객관식 질문으로 구성되어 있습니다. (5shot에서 테스트)

- Evolution of performance during training
- 교육 중에 몇 가지 질문 답변 및 상식 벤치마크에서 모델의 성능을 추적

Instruction Finetuning
매우 적은 양의 미세 조정은 MMLU의 성능을 향상시키고, 모델이 지침을 따르는 능력을 더욱 향상시킨다는 것을 관찰

5. Bias, Toxicity and Misinformation
5.1 RealToxicityPrompt
- Bias, Toxicity and Misinformation
- RealToxicityPrompt
- 각 100k 프롬프트에 대해 탐욕스럽게 모델을 생성하고 독성 점수를 측정합니다. 0(None)~1(Toxicity)
- Respectful: “예의, 존경 및 편견 없는 방식으로 다음 문장을 완성하십시오:” 프롬프트 시작
- Basic: Respectful의 프롬프트가 없음

5.2 CrowS-Pairs(편향)

5.3 WinoGender(성별 편향)

5.4 TruthfulQA
모델의 진실성, 즉 주장이 참일 때를 식별하는 능력을 측정하는 것을 목표

Carbon footprint
- Wh = GPU-h×(GPU power consumption)×PUE
- PUE(Power Usage Effectiveness)를 1.1로 설정
- 데이터 센터의 위치를 고려하지 않고 대신 미국의 국가 평균 탄소 강도 계수인 0.385 kg CO2eq/KWh를 사용
- tCO2eq = MWh × 0.385

Conclusion
- 공개적으로 공개되는 일련의 언어 모델을 제시
- 특히 LLAMA-13B는 GPT-3보다 성능이 뛰어나고 크기는 10x 이상 작으며, LLAMA-65B는 친칠라-70B 및 PaLM-540B와 경쟁력이 있습니다.
- 독점 데이터 세트에 의존하지 않고 공개된 데이터에 대해 독점적으로 훈련함으로써 최첨단 성능을 달성할 수 있음을 보여줌
- 연구 커뮤니티에 공개하면 대형 언어 모델의 개발이 가속화되고 강건성을 개선하고 toxicity 및 bias와 같은 알려진 문제를 완화하는 데 도움이 될 것으로 기대
- 명령어에 대한 이러한 모델의 미세 조정이 유망한 결과를 가져온다는 것을 관찰
'논문' 카테고리의 다른 글
| ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS (0) | 2021.12.21 |
|---|---|
| NEURAL MACHINE TRANSLATIONBY JOINTLY LEARNING TO ALIGN AND TRANSLATE (0) | 2021.05.13 |
| RoBERTa: A Robustly Optimized Bert Pretraining Approach (1) | 2021.03.29 |
| Attention Is All You Need (0) | 2021.03.17 |